
AIで社会・ビジネスはどう変わる?
この講義の続きはもちろん、
5,000本以上の動画を好きなだけ見られる。
ディープラーニングがもたらした「運動の習熟」
AIで社会・ビジネスはどう変わる?(2)3歳児になったAI
松尾豊(東京大学大学院工学系研究科 人工物工学研究センター/技術経営戦略学専攻長 教授)
ディープラーニングという新技術によって、AIの画像認識の精度は飛躍的に向上した。その成果は、コンピュータに「運動の習熟」と「言葉の意味理解」をもたらす。東京大学大学院工学系研究科特任准教授・松尾豊氏が、最先端の研究事例を紹介しながら、これまでの人工知能では成し得なかった様々な成果を語った。(2016年11月30日開催三菱総研フォーラム2016講演「AIで社会・ビジネスはどう変わるか?」より、全4話中第2話)
※テキストの文中に参考動画(YouTube)へのリンクがありますので、併せてご覧ください。
時間:12分02秒
収録日:2016年11月30日
追加日:2017年2月27日
収録日:2016年11月30日
追加日:2017年2月27日
カテゴリー:
≪全文≫
●ゲームのコツをつかむコンピュータ
ディープラーニングによる「認識の習熟」だけでも相当に大きな変化なのですが、他にも大きな変化がいろいろあります。次にお話しするのは、「運動の習熟」です。ロボットや機械の動作がだんだん上達していくということです。実はこれは、AlphaGoを開発したDeepMindという会社が、2013年ぐらいに行っていた研究で、ブロック崩しを学習するAIをつくっていました。
【参考動画1】
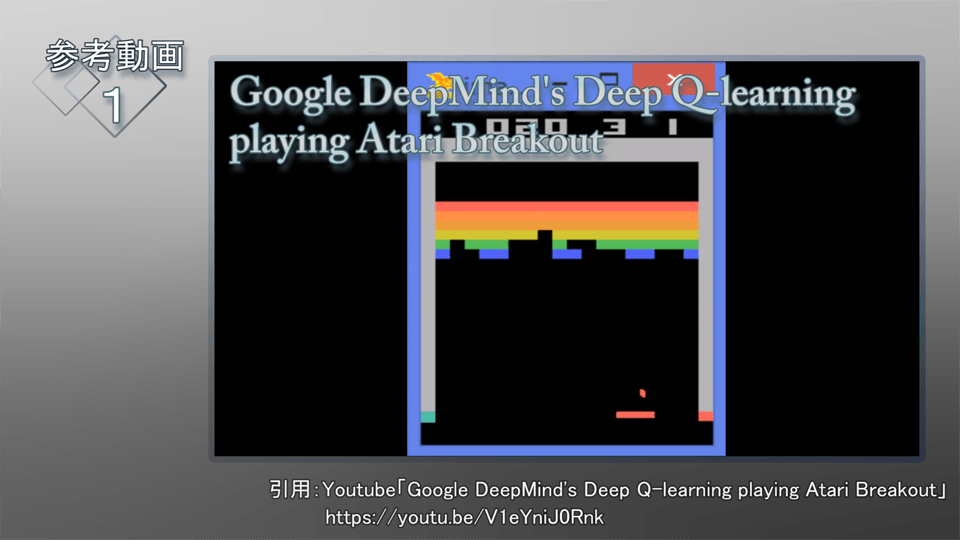
Google DeepMind's Deep Q-learning playing Atari Breakout
https://youtu.be/V1eYniJ0Rnk
ここで使われているのは、強化学習というやり方です。人工知能自身が、試行錯誤しながらだんだん上達していくというものです。最初は下手なのですが、だんだん上達してくるということが起こります。しばらくすると、すごく上手になります。このぐらい上達する程度ならば、昔のAIでもできました。ただ昔のAIでは、「これはボールだ」とか「これは自分(コンピュータ)が動かしているバーだ」ということを人間が定義していました。
ここでお見せしたAIがすごいのは、画像を入れているだけだということです。画像認識によって、「丸っこいものがある」とか「棒っぽいものがある」と認識し、それらのX座標が合っているとき、「点が入りやすい」ということを学んでいき、だんだん上達していきます。要するに、目で見て上達していくということを、AI自身がやっているのです。
そうすると、そのうち何が起こるか。AIが「コツを見つける」ということをやり始めるのです。AIは、画面の左端(ゲーム画面の4)を狙い始めます。左端・右端を狙って通路をつくり、ボールを上に放り込むとすごい点が入るので、実際にそれを狙っていくようになります。画像から特徴量を取り出してくるので、左端や右端に通路ができている状態が良い状態だということに気付いているのです。
これと全く同じプログラムを使えば、全然違うゲームを学習させることができます。例えばインベーダーゲームでも、全く同じプログラムを使って上達させることができるのです。
【参考動画2】
●ゲームのコツをつかむコンピュータ
ディープラーニングによる「認識の習熟」だけでも相当に大きな変化なのですが、他にも大きな変化がいろいろあります。次にお話しするのは、「運動の習熟」です。ロボットや機械の動作がだんだん上達していくということです。実はこれは、AlphaGoを開発したDeepMindという会社が、2013年ぐらいに行っていた研究で、ブロック崩しを学習するAIをつくっていました。
Google DeepMind's Deep Q-learning playing Atari Breakout
https://youtu.be/V1eYniJ0Rnk
ここで使われているのは、強化学習というやり方です。人工知能自身が、試行錯誤しながらだんだん上達していくというものです。最初は下手なのですが、だんだん上達してくるということが起こります。しばらくすると、すごく上手になります。このぐらい上達する程度ならば、昔のAIでもできました。ただ昔のAIでは、「これはボールだ」とか「これは自分(コンピュータ)が動かしているバーだ」ということを人間が定義していました。
ここでお見せしたAIがすごいのは、画像を入れているだけだということです。画像認識によって、「丸っこいものがある」とか「棒っぽいものがある」と認識し、それらのX座標が合っているとき、「点が入りやすい」ということを学んでいき、だんだん上達していきます。要するに、目で見て上達していくということを、AI自身がやっているのです。
そうすると、そのうち何が起こるか。AIが「コツを見つける」ということをやり始めるのです。AIは、画面の左端(ゲーム画面の4)を狙い始めます。左端・右端を狙って通路をつくり、ボールを上に放り込むとすごい点が入るので、実際にそれを狙っていくようになります。画像から特徴量を取り出してくるので、左端や右端に通路ができている状態が良い状態だということに気付いているのです。
これと全く同じプログラムを使えば、全然違うゲームを学習させることができます。例えばインベーダーゲームでも、全く同じプログラムを使って上達させることができるのです。

「科学と技術」でまず見るべき講義シリーズ

私たちにはなぜ宗教が必要だったのか…脳の働きから考える
長谷川眞理子
ヒトの進化史を文明の発展の時間軸から考える
長谷川眞理子
人気の講義ランキングTOP10
【10min解説】田口佳史先生×堀江重郎先生《老子の神髄》
テンミニッツ・アカデミー編集部